I wrote on this topic a decade ago, when the scientific community was already struggling to work with the burgeoning literature [1]. We faced roughly 2.5 million new papers published annually, that’s one every 13 seconds. The advice then was strategic: define your ‘why,’ apply the Four-Filter Triage System, and accept that you could only read deeply about 2% of your search results [2, 3].
That was the good old days.
Today, the literature has more than doubled in size in the last 10 years. Cumulative annual output now exceeds 4-6 million new articles, and the total searchable corpus (body of work) across databases like PubMed, Scopus, and Semantic Scholar may exceed 200 million documents [4]. A systematic literature review that might have once required screening 3,000 candidates now routinely confronts 12,000 or more. Manual screening at the historically reported rate of roughly two papers per minute would demand 100+ person-hours, nearly three full work weeks of uninterrupted effort [5].
However, although the volume has exploded, so have the technologies to manage it. The researcher of 2026 has access to capabilities that were unimaginable a decade ago – assuming they are prepared to learn how to use them. Large language models (LLMs) can classify abstracts with near-human accuracy. Semantic search tools can find relevant papers without exact keyword matches. Citation-context analysis can tell you not just that a paper was cited, but how, whether subsequent work supported, contradicted, or merely mentioned its findings.
The challenge is no longer "how do I find papers?" It is "how do I integrate AI assistance without losing scientific rigour?" The core principles from 2016 remain: you are not reading for curiosity but for ammunition, context, and credibility. But the workflow has been radically transformed.
Why 2016's Framework Broke
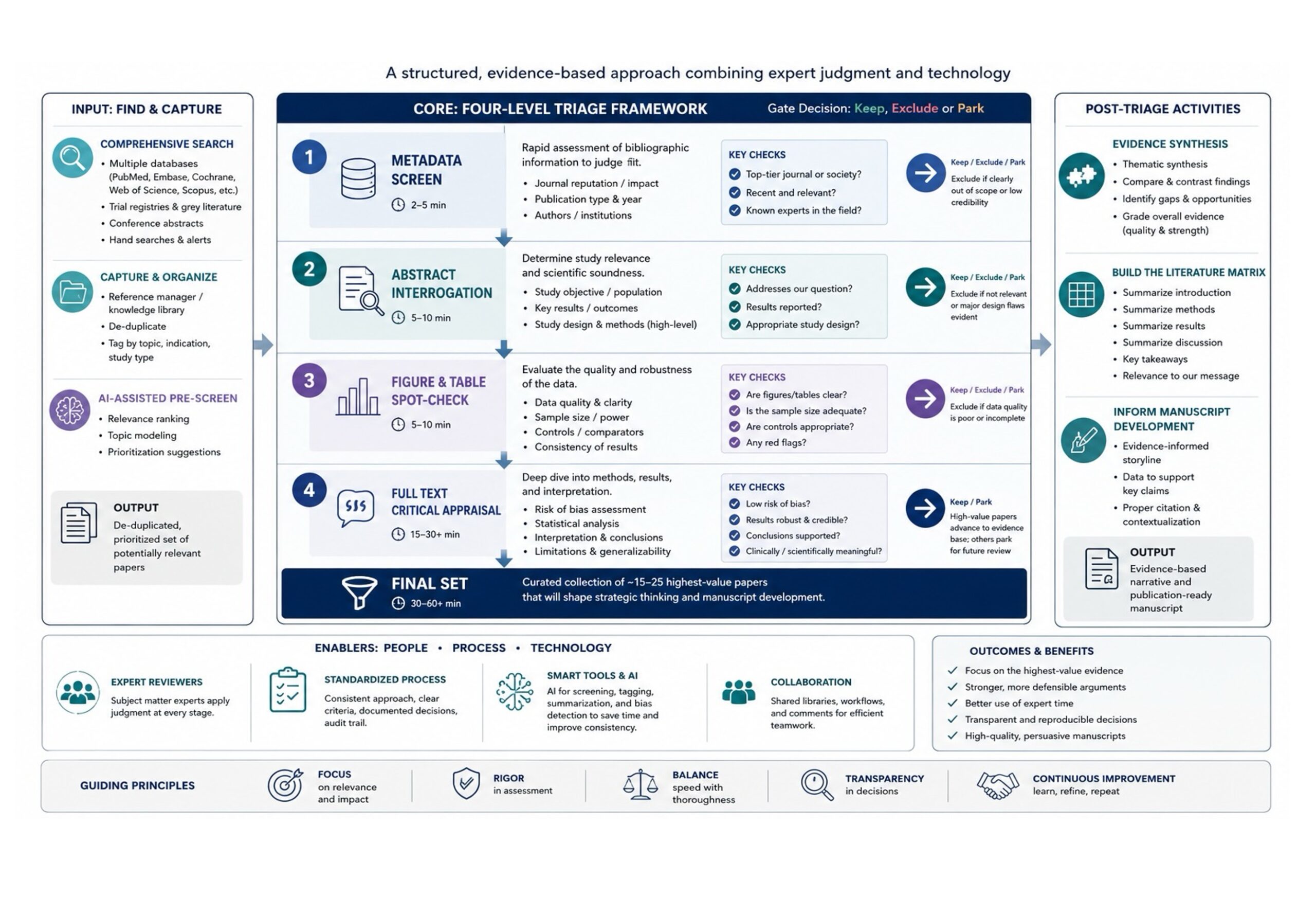
The Four-Filter Triage System from 2016 was great for its time. Metadata Scan → Abstract Interrogation → Figure Spot-Check → Citation Check. Each filter being manual, cognitive, and sequential. It worked beautifully when you had circa 1,800 search results. It collapses under 12,000+.
Today’s fundamental bottleneck is human attention. Each abstract requires 30 seconds of focused reading. At that rate, processing 10,000 abstracts demands 83 hours. No amount of discipline can speed that up. The second bottleneck is access: paywalled papers require individual PDF downloads, each taking time to locate, pay for and open. The third bottleneck is inconsistency: human ‘screeners’ employed to address large numbers of candidates, even experienced ones, disagree with each other on inclusion decisions approximately 10-15% of the time, requiring adjudication [6].
The new reality demands a different architecture: parallel processing, AI-assisted triage, and confidence-guided human oversight.
The AI-Enhanced Triage Pipeline (From 18,000 Papers to 25 Deep Reads)
The following pipeline integrates three categories of AI tools, each addressing a specific bottleneck. The human remains firmly in-the-loop, but not as a manual labourer, rather as a supervisor, calibrator, and final arbiter.
Stage Zero: Semantic Search
Traditional keyword search is brittle. If your terms do not match the authors' vocabulary, you miss relevant papers. Semantic search solves this by embedding the meaning of your query and finding papers with conceptually similar content, irrespective of exact wording [7].
Tools to use: Elicit, Consensus AI, or Semantic Scholar. Elicit can searche over 138 million papers and 545,000 clinical trials using semantic similarity [8]. Consensus provides a "Consensus Meter" that visually synthesizes whether the evidence supports, contradicts, or is uncertain about your specific question [8].
Time saved: Instead of iterating through 15 different keyword combinations (hours of work), you run one semantic query (30 seconds). The initial candidate set is also more relevant, reducing downstream filtering.
Mass Abstract Screening with LLM Consensus
This stage replaces the manual "Filter Two" (Abstract Interrogation) from 2016. Instead of you reading every abstract, you deploy multiple LLMs to classify each paper based on your inclusion criteria.
How it works: You provide the LLMs with a prompt that operationalizes your inclusion/exclusion criteria (e.g., "Include if this paper reports original human research on measles vaccination efficacy in children under five. Exclude if it is an editorial, review, or animal study."). Each LLM, you should use at least three, ideally from different architectures (e.g., Chat GPT-4o, Llama 3.1, and Claude), classifies each paper's title and abstract independently [9].
Consensus scheme: Because individual LLMs can make errors, you implement a voting mechanism. A conservative approach for high-stakes reviews (where missing a relevant paper is dangerous) is to include a paper if any LLM votes for inclusion. Only papers where all LLMs vote for exclusion are automatically removed [9].
Validation: In a 2025 study using 8,323 candidate papers, this consensus-based LLM screening achieved lower error rates than single human annotators while reducing manual effort by over 70% [8]. For living systematic reviews, agentic AI pipelines have demonstrated the ability to increase sensitivity to 86–95% depending on workload reduction thresholds [10].
Human-in-the-loop calibration: Before running the full corpus, you conduct a fine-tuning phase. To achieve this, you manually screen a small subset (100–300 papers) and compare your decisions to the LLM votes. Where you disagree, you analyse the reasoning and refine your prompts. This iterative calibration dramatically improves performance [10].
Time saved: Manual screening of 10,000 abstracts at 30 seconds each = 83 hours. LLM-assisted screening reduces manual review to a 300-paper calibration set (2.5 hours) plus a small number of low-confidence edge cases. Net time: approximately 4 hours, a 95% reduction.
Citation-Context Analysis (Replaces Simple Citation Counts)
The 2016 framework used citation counts as a proxy measure for ‘influence.’ But a high citation count can mean a paper is influential because it is correct—or because it is wrong and everyone is arguing against it. You need to know the difference.
Scite is an AI-powered platform that helps researchers discover and evaluate scientific literature through Smart Citations, showing whether studies support or contradict a claim.
Tools to use: Scite analyses over 1.2 billion citation statements, classifying each as supporting, contradicting, or merely mentioning the cited paper [8][11]. A paper that has been contradicted by subsequent high-quality studies should be treated with scepticism irrespective of its raw citation count.
How it works: For each paper that survives Stage One, you retrieve its citation-context profile. The tool shows you the distribution of supporting vs. contradicting citations, with direct links to the citing papers. This allows you to assess the paper's reception by the field, not just its visibility.
Human judgment required: Scite does not tell you the quality of the supporting or contradicting papers. A paper contradicted by one large RCT and supported by ten small, underpowered studies is still likely wrong. You must evaluate the evidence behind the citations. But Scite gives you the starting point, a map of the intellectual terrain, in seconds rather than weeks.
Time saved: Manual citation tracing (finding who cited a paper, reading those papers to see what they said) previously took hours per key paper. When used correctly, Scite can reduce this to seconds.
LLM-Assisted Value Extraction
The 2016 "Value Inventory" (Signal, Architectural, Narrative) remains an excellent value framework. But the extraction process can now be augmented and accelerated.
Tools to use: Elicit allows you to define custom columns (e.g., "sample size," "primary outcome," "effect size," "limitations stated") and automatically extracts this information from the full text of up to 50 papers at a time [8]. It populates a table that you can sort, filter, and export.
Critical caveat: LLM extraction is not perfect. You must spot-check the outputs against the original papers, particularly for numeric data and methodological details. The time savings come from eliminating manual data entry for straightforward fields, not from abdicating verification.
Human-in-the-loop verification: For your top 5–10 papers, you still need to perform a full deep dive—reading the methods section, checking controls, evaluating sample sizes. No AI currently has the domain expertise to assess whether a specific control condition was appropriate for a specific biological question.
Part Three: The Integrated Workflow – A Step-by-Step for 2026
Total time budget for a 18,000-result search: 12–15 hours (compared to 80+ hours manually).
| Step |
Tool(s) |
Human Action |
Time |
| 1. Semantic Search |
Elicit, Consensus AI, Semantic Scholar |
Formulate research question as natural language query. Run search. |
0.5 hr |
| 2. LLM Consensus Screening |
LLMSurver, custom GPT pipeline, or GREP-Agent |
Define your inclusion criteria as structured prompt. Run on 200-paper calibration set; refine prompt based on disagreements. Then run on full corpus. Review only low-confidence/edge cases. |
3–4 hrs |
| 3. Citation-Context Filtering |
Scite |
For qualifying papers, review supporting/contradicting profiles. Flag papers with substantial contradictions for deeper scrutiny. |
1–2 hrs |
| 4. Value Extraction |
Elicit AI (extraction tables) |
Define extraction columns. Run on 20–30 high-priority papers. Spot-check outputs. |
2 hrs |
| 5. Human Deep Dive |
None (your brain) |
Read methods, scrutinize figures, assess controls for top 5–10 papers. Build Literature Matrix. |
5–6 hrs |
The Risks You Cannot Automate Away
AI tools are not magic. They have specific, well-documented limitations that you need to manage actively.
Risk One: Hallucination. LLMs fabricate information. They may generate plausible-looking citations that do not exist, oand/r extract numbers that are not present in the source text [6]. Mitigation: Never trust an AI extraction without verification. Use AI for speed, not authority.
Risk Two: Automation Bias. Humans have a documented tendency to trust algorithmic outputs even when they contradict their own judgment [7][12]. If an AI confidently classifies a paper as "exclude," you may stop thinking about it. Mitigation: Design your workflow to require explicit human sign-off on all exclusions below a confidence threshold. The Loon Lens platform, for example, flags low- and medium-confidence ‘Include’ calls for human review (approximately 5.8% of citations), which increased precision from 63% to 90% while preserving 99% sensitivity [6].
Risk Three: Dataset Limitations. Most AI tools search only open-access content or abstracts unless your institution has special agreements [4][7]. You will miss relevant papers that are locked behind paywalls and not in the tool's index. Mitigation: Use AI tools as a pre-filter, but run a parallel conventional search in your institution's subscription databases (PubMed, Scopus, Web of Science) for your final candidate list.
Risk Four: Semantic Misunderstanding. LLMs do not understand cause-and-effect or physical laws. They calculate the most likely next word based on statistical patterns. They can summarise a paper's claims perfectly while being entirely unable to assess whether those claims are biologically plausible [7]. Mitigation: Never delegate critical appraisal to AI. The deep dive activities like assessing controls, evaluating sample size adequacy, identifying confounding variables, remain a human-only task.
Part Five: The Human-in-the-Loop
The phrase "human-in-the-loop" appears throughout the AI-assisted literature review literature. But what does it actually mean?
A genuine human-in-the-loop system satisfies three conditions [13]:
- Explicit human role: You are not a passive recipient of AI outputs. You actively supervise, calibrate, and override decisions.
- Explicit interaction point: The system specifies where your input enters the pipeline (e.g., prompt engineering, fine-tuning calibration, confidence threshold setting, final adjudication).
- Loop effect: Your input actually changes the model's subsequent behaviour or the final decision.
In practice, this means:
- You write and iteratively refine the prompts that the LLMs use to classify papers.
- You review a calibration set of 200–300 papers, comparing your decisions to the LLMs', and use disagreements to improve your prompts.
- You set confidence thresholds that determine which papers require your manual review (e.g., "automatically accept all 'Very High Confidence Excludes' without review; manually review everything else").
- You adjudicate edge cases where LLMs disagree or express low confidence.
- You perform the final deep dive on papers that will be central to your manuscript.
The AI does not replace you. It handles the repetitive, high-volume, low-judgment tasks (screening thousands of abstracts). You handle the strategic, nuanced, high-judgment tasks (assessing biological plausibility, evaluating experimental design, synthesizing contradictory evidence into a coherent narrative).
A Revised Time Budget for 2026
The 12-Hour Rule from 2016 assumed a 20-paper deep dive and a 1,963-result search [1]. For 2026, with circa 18,000 results and AI assistance, here is a realistic budget:
| Phase |
Time |
| Semantic search and tool setup |
1 hour |
| Prompt engineering + calibration set review (200 papers) |
3 hours |
| LLM consensus screening (full corpus) |
1 hour (computational) + 2 hours reviewing low-confidence edges |
| Citation-context analysis for survivors |
1 hour |
| AI-assisted value extraction (30 papers) |
2 hours |
| Human deep dive (top 8 papers) |
4 hours |
| Literature Matrix construction |
1 hour |
| Total |
15 hours |
Compare to manual 2016 baseline for the same corpus size: 18,000 abstracts × 30 seconds each = 150 hours just for abstract screening, before any full-text reading. The AI-assisted workflow achieves approximately a 90% reduction in human time while maintaining or improving accuracy [5][6][9].
Conclusion
The 2016 guide concluded with the Lego wall analogy: every paper you internalize is a brick in your unique structure of knowledge. That remains true. But in 2026, you are no longer laying each brick by hand. You have a team of intelligent assistants handing you bricks, sorting them by colour and shape, flagging which ones might be cracked, and helping you see the overall wall taking shape.
The goal has not changed. You still need to identify the key findings, the reliable methods, the gaps your manuscript will fill. You still need signal, architectural, and narrative value. You still need contradictions to resolve and methods to borrow. This approach doesn’t wholly replace the old way of doing things [1][14]. Adapting to new technologies takes time and resources that may only be worthwhile investing if you are kicking off a large-scale project and you have broad institutional access to publications locked behind paywalls.
But in the right circumstances you can change markedly the ratio of human to machine effort. You now spend your cognitive energy where it matters most: on calibration, on critical appraisal, on synthesis, on the creative leap of seeing what the literature does not say. The machines handle the volume.
The researcher who masters this partnership, who knows when to trust the AI and when to override it, who can write a precise prompt and recognize a hallucination, who treats the tools as assistants rather than oracles, see substantial efficiency gains.
References
- Hardman TC. (2016). A Strategic Framework for Mastering the Literature
- Elwood TW. Is Too Much Enough? J Allied Health. 2016;45(2):79.
- Pew Research Center. Health issues topped the list of scientific studies reaching wide audiences in 2016. Pew Research Center. December 28, 2016.
- Oregon State University Libraries. Comparison of AI Literature Review Tools. LibGuides. Updated April 23, 2026.
- Wallace BC, et al. The number of person-hours required for manual title and abstract screening in systematic reviews. In: Leveraging LLMs for semi-automatic corpus filtration in systematic literature reviews. ScienceDirect. 2026.
- Johns G, Uttaro M, Maclean J, et al. Validating Loon Lens 1.0 for Autonomous Abstract Screening and Confidence-Guided Human-in-the-Loop Workflows in Systematic Reviews. Value in Health. 2025;28(11):1630-1636.
- London School of Economics and Political Science. Literature Review: Software Platforms Dedicated to Literature Search and Review. LSE Data Science Institute. 2025.
- Best AI tools for medical research 2026: Elicit, Consensus, Semantic Scholar, Perplexity, and scite. iatroX Blog. March 19, 2026.
- LLMSurver Study Team. Leveraging LLMs for semi-automatic corpus filtration in systematic literature reviews. Computers & Graphics. 2026;135:104537.
- GREP-Agent Study Group. Enhancing Evidence Synthesis Efficiency: Leveraging Large Language Models and Agentic Workflows for Optimized Literature Screening. Health Economics Review. 2025;3(6):e70042.
- Smart Citations: Supporting, Mentioning, or Contrasting Citations. scite.ai. Accessed 2026.
- Ethical and governance considerations for AI in health. World Health Organization. 2024.
- Human-in-the-loop AI in the energy sector: a systematic review of paradigm shifts toward Industry 5.0. Energy and AI. 2026
- Niche Science & Technology Ltd. (2015). An Insider’s Insight into Literature Searches.