One of the unique strengths of the PCMG Annual Conference that I have been attending this week is that it offers far more than a series of ground-breaking presentations. At its best, it provides an opportunity to witness ideas that challenge fundamental assumptions about how our industry operates and where it is heading. In an era defined by artificial intelligence, geopolitical uncertainty, escalating development costs, regulatory transformation, and unprecedented scientific opportunity, the pharmaceutical industry finds itself navigating what can only be described as a perfect storm.
This year’s Day 1 presentations from Thomas Senderovitz (Danish Association of the Pharmaceutical Industry), Thomas Hartung (John Hopkins University), Richard Young (Cluepoints), and Amar Shah (Deloitte LLP) drew attention to challenges that extend far beyond medical communications. Together, they painted a picture of an industry standing at a crossroads, facing questions of global, strategic, and even existential importance. While the individual topics ranged from regulatory innovation and AI-enabled discovery to data science and the future of drug development, a common theme emerged: our relationship with data is fundamentally broken.
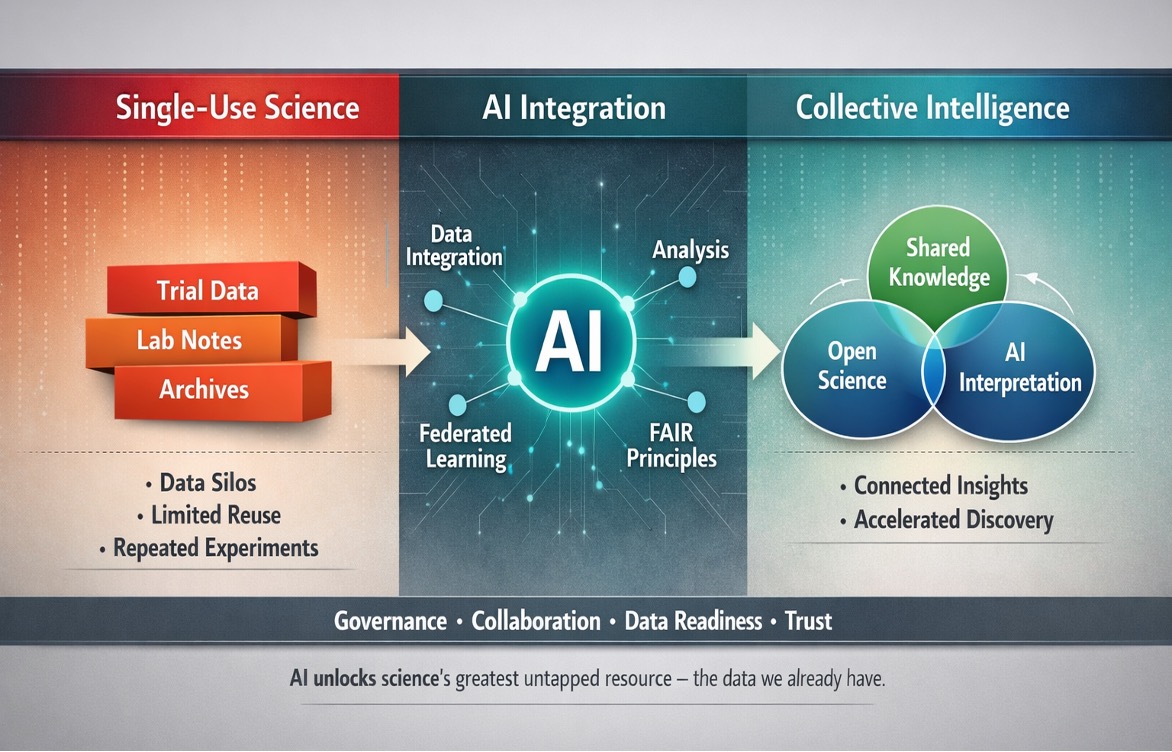
For decades, biomedical research has operated on a fundamentally inefficient model. Data from clinical trials, animal investigations, and preclinical studies follows a predominantly ‘single-use’ trajectory, generated, interpreted, published, and archived, rarely to be accessed again. When a new investigator wishes to build upon prior work, the default path is to formulate a new hypothesis and commence fresh experimentation, unable to access the wealth of information already captured in historical datasets. This represents not merely a missed opportunity, but a profound inefficiency that slows scientific progress and drives up the cost of science while slashing return on investment. With the emergence of large language models (LLMs) and advanced artificial intelligence, we are witnessing the beginning of a paradigm shift—one that promises to transform how we interact with scientific data, moving from a single-use model to a dynamic ecosystem of continuous learning and discovery.
The High Cost of Single-Use Science
The inefficiency of current research practices has been well-documented. A 2025 study of laboratory professionals found that 65% reported repeating experiments or assays because they could not easily find or reuse previous results with confidence [1]. This "repetition tax" represents a substantial drag on productivity, consuming resources that could otherwise be directed toward novel investigation.
The root causes are multifaceted. Scientific data is often stored in fragmented, inaccessible silos, with researchers spending hours searching across scattered sources, lab journals, institutional archives, and internal databases, to locate relevant prior work. Even when data is found (and you can get access to it), interpretation remains a disconnected step; the same study noted that 81% of scientists agreed that their electronic lab notebooks record data but do not help them interpret it [1]. This fragmentation ensures that for much of development, data truly serves only one purpose, limiting its potential to inform new hypotheses.
In the pharmaceutical industry, the situation has seen modest improvement. Companies increasingly combine in-house and related clinical and preclinical datasets for regulatory submissions, and in recent years, major pharmaceutical organisations have begun interrogating their historical data archives to identify new opportunities. However, this still represents a fraction of the potential value locked within existing research outputs [2].
IP Fences and Literature Barriers
The challenge extends beyond large organisational silos. A vast expanse of data from the biotechnology sector remains inaccessible, protected behind intellectual property fences. Alone, smaller companies, lack the resources to generate and curate massive datasets. This introduces a fundamental hurdle: they simply do not have access to the large-scale, high-quality data needed to train effective AI models or inform critical biotech development decisions [3].
The scientific literature presents its own barriers. Historical research is often difficult to access, locked behind paywalls or buried in archives. Even when accessible, extracting meaningful insights from millions of published papers requires a scale of effort that is beyond human capacity alone [4]. This ‘literature lock’ means that valuable findings remain isolated, failing to inform subsequent research and development. However, at least AI is providing opportunities to better interrogate this massive intellectual corpus (the whole of the scientific literature), something one single individual working alone would find close to impossible due to its scale [4].
AI: The Key to Unlocking Data Value
Artificial intelligence is emerging as the transformative tool capable of addressing these long-standing challenges. The introduction of LLMs is reducing the need for perfectly structured data, making it possible to combine datasets from diverse sources that were previously incompatible. This capability opens the door (just a crack) to massive scientific advances that would have been inconceivable with traditional analytic methods.
One of the most significant breakthroughs is the ability to process unstructured data. Clinical notes, radiology reports, and pathology documentation contain a wealth of information that has historically been inaccessible for large-scale analysis. This is changing. For example, a recent implementation of an LLM-based extraction pipeline successfully processed 1,800 MRI reports with a 100% completion rate, extracting 16 structured clinical elements from each document at an average cost of just $0.009 per report [5]. This represents a dramatic improvement over manual abstraction, which is time-consuming, produces data of variable quality and requires almost limitless resources.
Similarly, studies in hepatology have demonstrated that LLMs can identify the presence of metabolic dysfunction-associated steatohepatitis (MASH) from clinical notes with F1-scores reaching 90.5% and extract key diagnostic measurements with over 99% accuracy [6]. These models can process more than 1,000 notes per hour, compared with approximately 20 notes per hour for manual review, at a cost of roughly $0.012 per note [6].
These amazing initiatives are not limited to clinical data. The same approaches can be applied to preclinical research, unlocking insights from historical experiments and enabling researchers to learn from work that was previously considered complete and closed.
Collaborative Innovation: Breaking Down Data Silos
There has been some success with academic data sharing initiatives that have evolved from small-scale disciplinary repositories into global infrastructures for open science. Their origins are rooted in the broader open access and open science movements of the late 20th century, driven by the need to make research outputs more transparent, reproducible, and collaborative. Over the last few decades the scope has expanded:
- Early disciplinary repositories (1960s–1990s): Data sharing began informally within scientific communities. Fields such as astronomy, genomics, and social science developed shared databases because collaboration depended on pooling large datasets. Examples include:
- The creation of large scientific data archives in astronomy and earth sciences.
- International genomic data-sharing efforts associated with the Human Genome Project (1990–2003), which established norms for rapid public release of biological data.
- Open access and open data movement (2000s): The rise of digital publishing and internet infrastructure accelerated formal data-sharing policies:
- The Budapest Open Access Initiative (2002) and related movements established principles for freely accessible scholarly outputs.
- Research funders increasingly required researchers to share data generated with public funding.
- Universities began developing institutional repositories and research data management policies.
- Research data infrastructure (2010s): The focus shifted from simply publishing datasets to creating systems that make data findable, accessible, interoperable, and reusable (FAIR). The FAIR data principles, introduced in 2016, became a major framework for modern data stewardship.
Academic data sharing has moved through three broad phases:
- Collaboration phase (pre-2000): researchers shared data mainly within specialist communities.
- Open data phase (2000–2015): repositories and funder policies encouraged wider access.
- Trusted data ecosystem phase (2015–present): focus is on FAIR data, governance, AI readiness, and sustainable infrastructures.
Can industry do the same?
Recognising the power of shared data, some organisations are beginning to break down traditional barriers. In September 2025, Eli Lilly launched TuneLab, an AI platform that provides biotechnology companies access to drug discovery models built on more than $1 billion of Lilly's internal R&D data [3][7]. The platform employs federated learning, a privacy-preserving approach that enables biotechs to benefit from AI models without directly exposing their proprietary data or Lilly's [3].
This represents a significant step toward collaborative innovation that circumvents traditional intellectual property hurdles. As Nisha Nanda, Group Vice President of Lilly Catalyze360, observed: "For many early-stage biotech companies, the promise of AI and machine learning in drug discovery remains just that, a promise" [7].
The Challenges Ahead
Despite the enormous potential, the transition to an AI-driven data reuse ecosystem is not without challenges. Data quality remains a primary concern. Leaders from pharmaceutical companies and academic institutions have converged on a critical insight: the challenge is not data volume but data readiness [2]. Poorly curated datasets produce unreliable predictions irrespective of model sophistication. Organisations must invest in data curation, contextualisation, and alignment with specific discovery questions to realise the full value of AI.
Governance frameworks are also essential. As AI integrates deeper into workflows, accountability and regulatory alignment become critical [2]. Questions about model provenance, decision logic, and validation against experimental outcomes must be addressed to build trust in AI-generated insights.
Furthermore, the rise of AI bots that indiscriminately scrape open scientific data raises concerns about data misuse, privacy, and the potential for researchers to be ‘scooped’ by automated systems that generate results without proper attribution. As Richard Young famously quoted at PCMG 2026, “ I can unblind your study in three moves.” The scientific community will need to develop new norms and safeguards to ensure that the transition to AI-driven discovery serves the broader scientific good.
The Path Forward
For decades, virtually everyone in scientific research, including the pharmaceutical sector, have largely adopted a laissez-faire approach to scientific data. Vast quantities of information generated through preclinical studies, clinical trials, regulatory submissions, real-world evidence programs, and post-marketing surveillance have been treated as single-use assets. Historically, data has been generated at enormous cost, analysed to answer a specific question, archived, and then often forgotten. The result has been that valuable knowledge remains trapped within organisational silos, disconnected databases, unpublished reports, and inaccessible archives. Previously, there was no real means of combining these unstructured data sets – and then came AI.
The industry is moving decisively in the direction of data reuse. The AI in pharmaceuticals market is projected to grow from $3.8 billion in 2024 to $15.2 billion by 2030 [3], driven in large part by the push to make data more accessible and reusable.
The vision is clear: AI will enable researchers to ask better questions, test ideas more efficiently, and make more informed decisions. As Manuel Guzman, President of CAS, noted: "These tools are designed to support researchers by helping them ask better questions, test ideas more efficiently, and make informed decisions" [2]. At least in this context, rather than replacing human expertise (stealing your jobs), AI expands the scope of what researchers can explore, while domain experts maintain control over validation, interpretation, and strategic direction.
The transformation from a single-use to a multi-purpose data ecosystem is underway, promising to make scientific research and development exponentially more efficient. The opportunity is immense, if we can navigate the challenges of data readiness, governance, and collaboration to realise the full potential of AI in unlocking science's greatest untapped resource: the data we have already generated.
References
- Brook T (2026). The crisis of reuse: Why 65% of experiments are being repeated.
- AI in drug discovery: Moving from potential to practical. CAS.org. 2026.
- Lilly launches TuneLab platform to give biotechnology companies access to AI-enabled drug discovery models built through over $1 billion in research investment. Nasdaq. 2025
- Hardman TC (2026). A Strategic Framework for Mastering the Literature Revisited.
- Development and Validation of a Generative Artificial Intelligence-Based Pipeline for Automated Clinical Data Extraction From Electronic Health Records: Technical Implementation Study. Sciencedirect. 2026
- Large Language Models can Identify the Presence of MASH and Extract VCTE Measurements from Unstructured Documentation. SpringerLink. 2025.
- Lilly launches TuneLab platform to give biotechnology companies access to AI-enabled drug discovery models built through over $1 billion in research investment. Eli Lilly and Company. 2025.